
Продолжаем публиковать цикл статей, подготовленных совместно с российской компанией Loginom Company (профессиональный разработчик продуктов и решений в области анализа данных), посвященных Кредитному скорингу.
В первой нашей статье мы уже разобрали понятие Кредитного скоринга, а в этой и нескольких следующих будем рассматривать вопрос построения скоринговой модели.
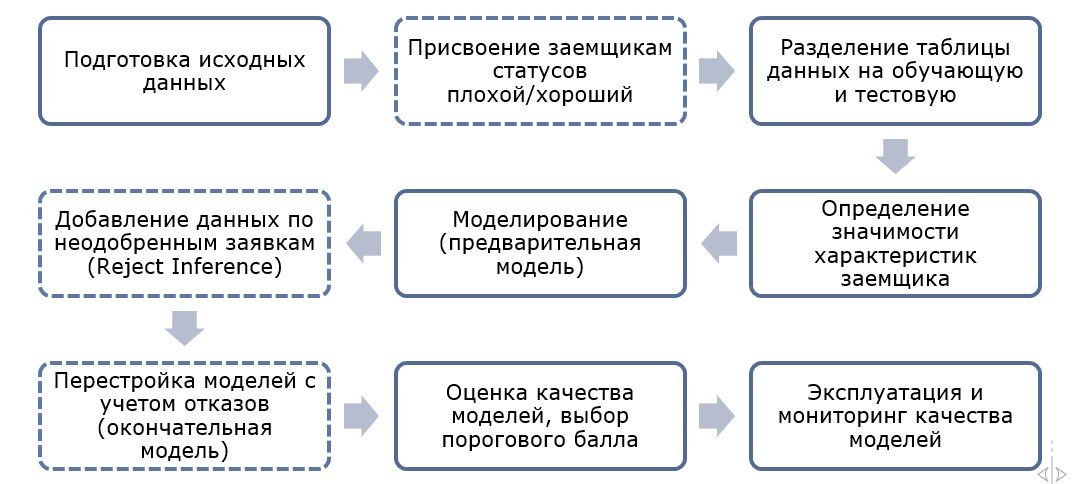
Процесс построения скоринговой модели можно представить в виде последовательности этапов.
Для построения скоринговой модели потребуются данные о заемщиках по рассматриваемому кредитному продукту за последние несколько периодов. Что принять за период, зависит от вида бизнеса и предлагаемого продукта. Для микрокредитной организации может оказаться достаточной глубина историчности 8 месяцев, для ипотечного кредита банка может потребоваться более 5 лет.
В качестве продукта для целей скоринга могут выступать любые формы отношений кредитора и заемщика, включая предоставление товарного кредита, рассрочки платежа, гарантии и поручительства.
Подготовка данных
В начале пути всегда неизвестно, какие данные о заемщике окажутся в итоге значимыми, а какие — нет. По этой причине формируется максимально широкий профиль будущего заемщика из всех имеющихся в распоряжении данных. Не стоит пренебрегать возможностью обогатить профили клиентов достоверными данными из доступных внешних источников. Например, это могут быть данные органов власти, бюро кредитных историй, телекоммуникационных компаний, социальных сетей и т.д.
Далее следует проверить собранные данные на пригодность для анализа. Правила проверки обычно довольно просты. Например, поле, содержащее только пустые значения, непригодно для анализа. Такой же вывод следует в отношении поля, заполненного одним значением. Числовые поля должны содержать цифры, текстовые — буквы. Ряд полей обычно требуют корректировки в виде заполнения пропущенных значений, корректировки аномалий, устранения противоречий. Эти действия уже требуют некоторой специальной подготовки и применения определенных алгоритмов.
Присвоение статусов заемщикам
Одна из основных целей скоринга – максимально точное разделение потенциальных заемщиков на категории «плохой»/«хороший». Для этого надо правильно обучить будущую модель на реальных примерах, где каждому заемщику уже присвоен такой статус. Если заемщик ушел в дефолт и перестал платить или, напротив, не допускает просрочек, со статусами все понятно. Сложнее всего разобраться с так называемой «серой» зоной», когда клиент допускает просрочки различной длительности, затем возвращается к нормальному графику платежей и снова допускает просрочки. Необходимо наблюдать за поведением такого заемщика до тех пор, когда он окончательно проявит свой статус. Этот промежуток времени называют периодом вызревания.
Наблюдая переходы заемщиков из одной категории просрочек в другую можно сделать обобщение и зафиксировать событие, после которого заемщики уже не возвращаются к нормальному графику платежей. По наличию/отсутствию такого события в кредитной истории заемщиков можно проставить статусы «плохой»/«хороший». Эту процедуру называют разметкой.
Разделение таблицы данных на обучающую и тестовую
Для проверки качества построенной модели требуется разделить исходную таблицу как минимум на две части. На одной части проводится обучение модели в том смысле, что алгоритм запоминает обнаруженные закономерности. На второй части проводится проверка адекватности, т.е. при обнаружении уже ставших известными закономерностей модель делает адекватные выводы. Разделение таблицы обычно выполняется в соотношении: 70% — обучающая и 30% — тестовая. Для обучения скоринговой модели требуется примерное равенство «плохих» и «хороших» заемщиков в обучающей части данных. В реальности такое соотношение встречается крайне редко. Обычно «плохих» заемщиков на порядок меньше чем «хороших». Для балансировки есть специальные методы, которые не вносят искажений в процесс обучения модели. В тестовой части необходимо сохранение всех свойств первоначальной таблицы.
Определение значимости характеристик заемщика
Общее число характеристик заемщика может исчисляться сотнями. Для построения модели требуются не все характеристики, а только те, которые вносят наибольший вклад в способность модели разделять «плохих» и «хороших» заемщиков. Такое свойство характеристик заемщика оценивается численно путем расчета информационного индекса (Information Value, IV). Например, среди мужчин и среди женщин одинаковый процент «плохих» заемщиков. Это означает, что характеристика «Пол» не имеет статистической значимости, информационный индекс равен нулю и для построения модели эта характеристика не потребуется. Если люди, состоящие в браке, допускают существенно меньше дефолтов чем одинокие, то у характеристики «Семейное положение» высокая значимость и высокий информационный индекс.
Моделирование
Для построения скоринговой модели все значимые характеристики необходимо подать на вход алгоритма, который способен оценивать наиболее вероятный из двух возможных исходов. Такой способностью обладают алгоритмы логит-регрессии, дерева решений, нейронной сети и ряд других алгоритмов. Выбор алгоритма классификации важен, однако, решающий вклад в качество скоринговой модели вносят изначальное распределение события дефолта внутри характеристик заемщика и качество подготовительной работы с данными.
Продолжение следует …
Справка:
Loginom Company — Ведущая российская компания, специализирующаяся на разработке систем для глубокого анализа данных, охватывающих вопросы сбора, интеграции, очистки данных, построения моделей и визуализации. Помогаем внедрять инновации, принимать более обоснованные и правильные управленческие решения для увеличения прибыли, снижения затрат и предотвращения рисков как коммерческим, так и государственным компаниям.

